3. What is Classification?
Classification is the process of allocating objects to a class within a discrete set of classes on the basis of data about that object and in accordance with a set of rules that create decision surfaces between the classes. It is usual that the classes are physically significant. Thus colour may be used to discriminate between oranges, lemons and apples on a process line, or waveband data may be used to create a land cover map from satellite image data.

Classification involves defining classes, usually by either defining training areas for each class, or automatically from the data itself. Then it involves setting the rules that define the decision surfaces that enables the classifier to decide on what data values belong to each class and finally it involves the actual conduct of the classification.
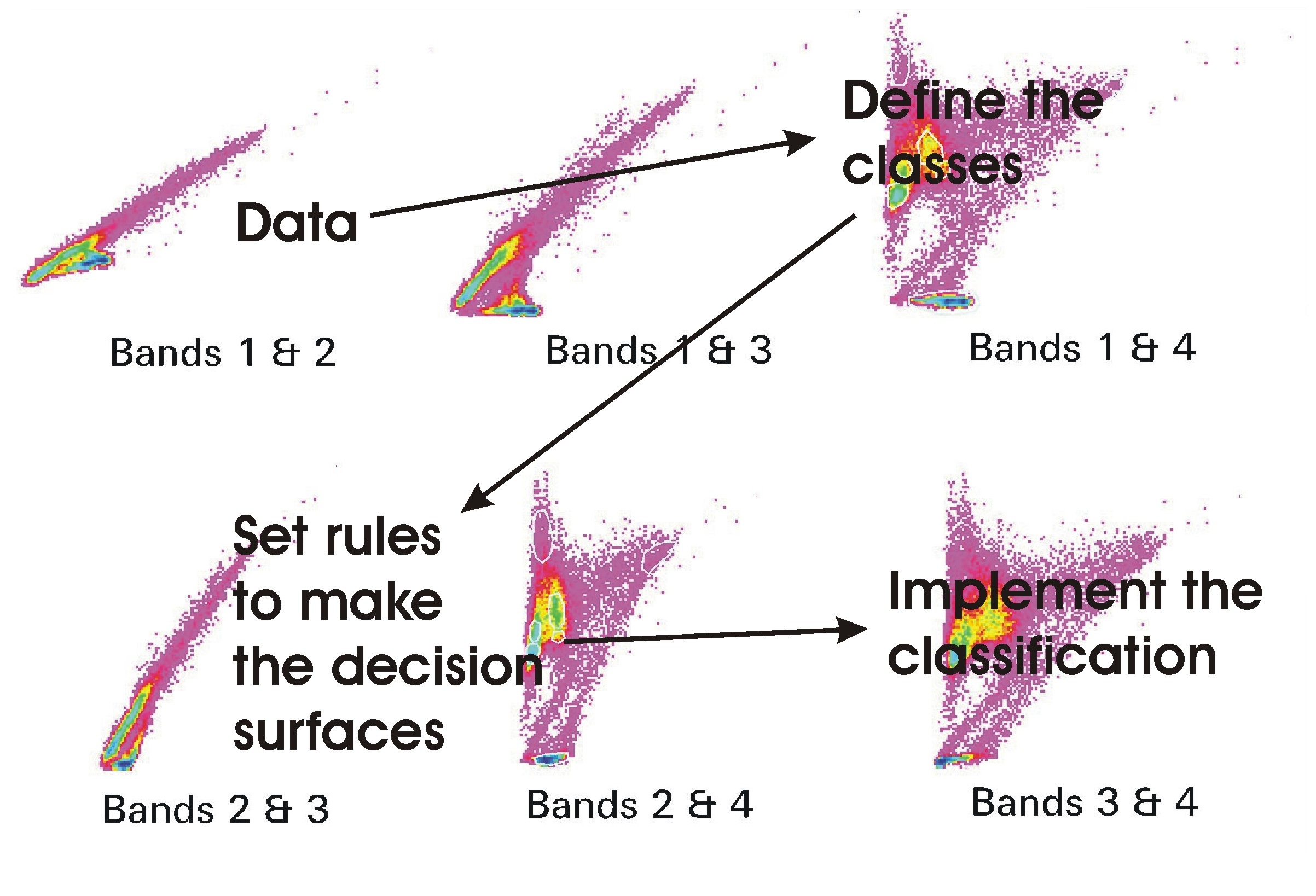
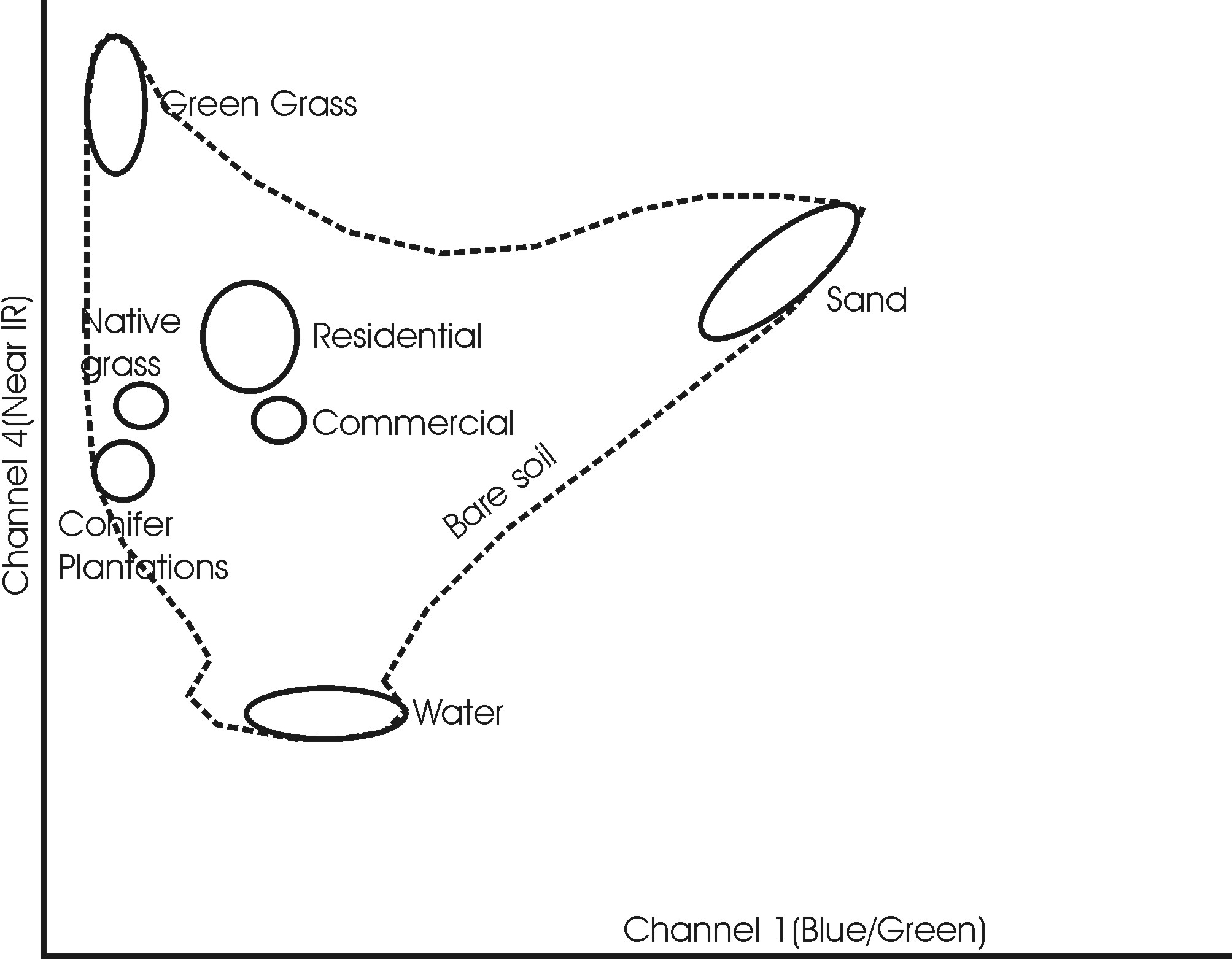
Classes are defined either by identifying typical areas for each class and then using training areas to get class statistics, or by using a clustering algorithm to identify clumps or clusters in the data, and then deriving statistics for each of these clusters. The first method is called supervised classification and the second is called unsupervised classification.
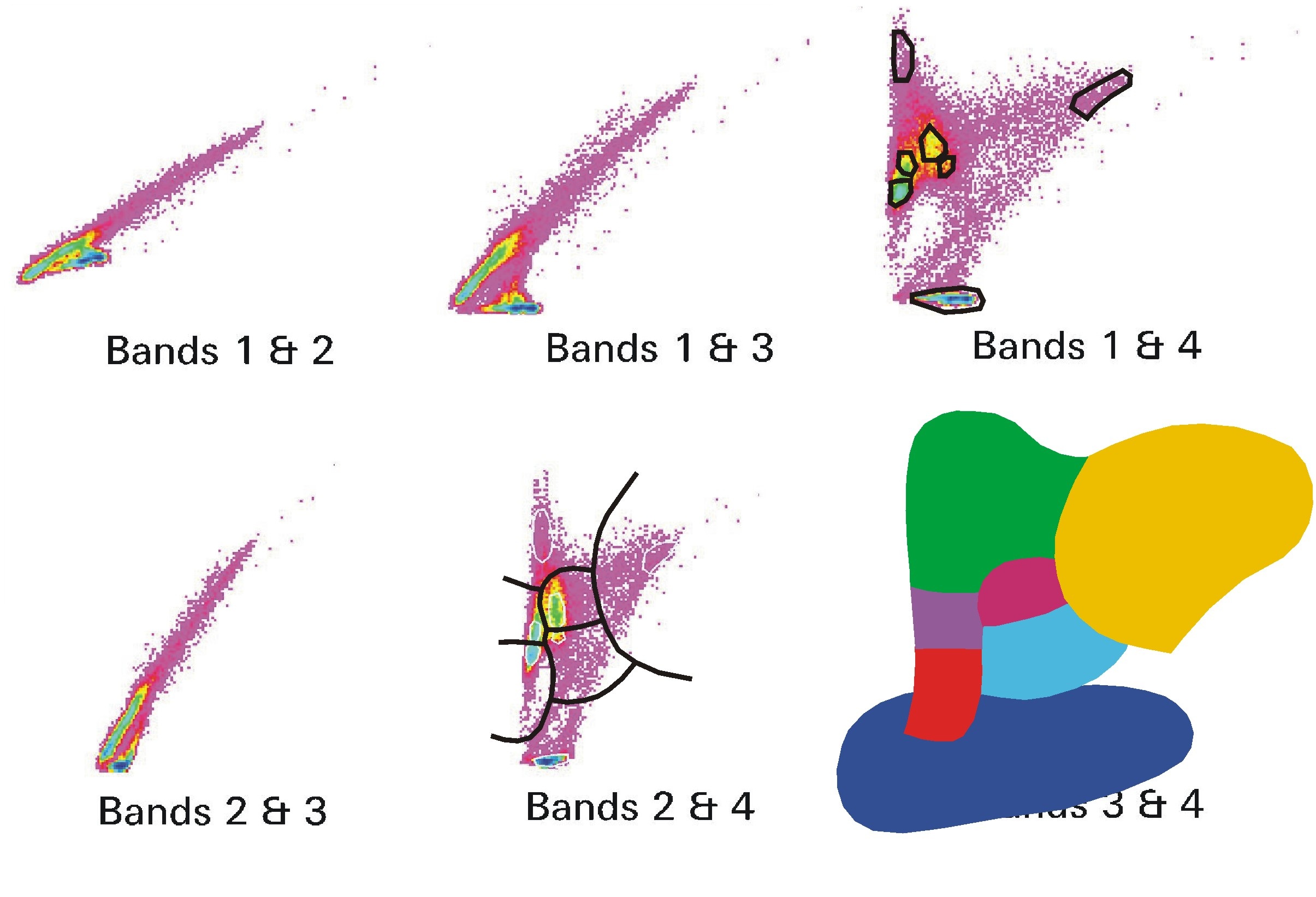
There are many ways to do this; we will focus here on parametric methods that assume that the data for a class obeys a standard model; usually the Normal Distribution.