6. Fehler und Kosten bei der Klassifizierung
Stellen wir uns vor, wir wollten zwischen zwei Klassen unterscheiden, welche normalverteilt sind, wie in der Abbildung rechts zu sehen ist.
In dieser Abbildung werden Pixel mit Werten, die links der Entscheidungsgrenze liegen, Klasse A zugewiesen und alle rechts liegenden Klasse B. Es ist jedoch schon zu sehen, dass dabei Fehler auftreten werden, da manche Pixel der Klasse A am rechten Ende der Kurve liegen und sich daher in der Fläche G befinden, ebenso wie einige Pixel aus Klasse B in der Fläche H liegen. Daher wird es bei einer Klassifizierung immer zu Fehlern kommen. Die Flächen G und H zeigen die Wahrscheinlichkeiten der falschen Klassifizierung der Pixel in den Klassen A und B an.
Die Fehlerrate kann verringert werden, indem man Daten nutzt, bei denen die verschiedenen Klassen einander weniger überlappen. Sobald jedoch Daten ausgewählt wurden, lassen sich die Fehler nicht mehr mindern; nur durch eine Änderung der Entscheidungsgrenzen ließe sich die Verteilung der Fehler ändern. Die Entscheidugsgrenze kann beispielweise so gesetzt werden, dass mehr Fehler in der einen Klasse auftreten, als in der anderen.
Üblicherweise wird die Entscheidungsgrenze so festgesetzt, dass die Wahrscheinlichkeiten der Fehlklassifizierung in beiden Klassen gleich groß sind, wobei dann Fläche G = Fläche H wäre, wie es bei der linken der in dem Diagramm dargestellten Entscheidungsgrenzen der Fäll wäre.
Es könnte aber auch sein, dass die mit der falschen Klassifizierung bei Klasse A verbundenen Nachteile viel größer sind, als die Kosten der Fehlklassifizierung in Klasse B. In diesem Fall wäre es natürlich besser, die Entscheidungsgrenze so zu verschieben, dass gilt:
(Wahrscheinlichkeit der Fehlklassifizierung von A) · (Kosten der Fehlklassifizierung A) = (Wahrscheinlichkeit der Fehlklassifizierung von B) · (Kosten der Fehlklassifizierung B)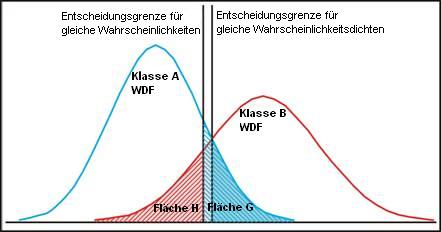
Sind die Kosten, also Nachteile, der falschen Klassifizierung bei A höher, als die Kosten durch falsche Klassifizierung bei B, dann stellt Fläche G die Wahrscheinlichkeit der Fehlklassifizierung von Klasse A dar und muss reduziert werden, was gleichzeitig eine Vergrößerung der Fläche H zur Folge hat.
Folglich: Fläche G · Kosten A = Fläche H · Kosten B
Wir haben bereits über Wahrscheinlichkeitsdichtefunktionen gelernt, dass:
also müssen wir die Entscheidungsgrenze anpassen, indem wir xd ändern, bis die in der ersten oberen Gleichung vorgegebene Bedingung erfüllt ist.
