6. Errors and Costs in Classification
Consider the case of where we are trying to discriminate between two classes, which are normally distributed as shown in the figure.
In this figure, pixels with values to the left of the Decision Surface will be allocated to Class A, and those to the right to Class B. But it can be seen that this will involve errors, since some pixels of Class A will occupy the right hand tail and thus occupy space G, just as some pixels from Class B will occupy the tail area H. Classification will thus always involve errors. Areas G and H show the probabilities of misclassification of pixels in classes A and B respectively.
The magnitude of the errors can be changed by using data with less overlap between the classes. However, once the data has been selected, then the errors cannot be reduced; but changing the decision surface can change the distribution of the errors, for example by placing the decision surface so that more errors occur in one class than in the other class.
It is usual to set the decision surface so that there are equal probabilities of misclassifying both classes, where Area G = Area H, the left hand of the two decision surfaces depicted in the figure.
It may be the case that the costs associated with misclassifying Class A are much higher than the costs associated with misclassifying Class B. In this case it would be better to move the decision surface so that:
(Probability of misclassifying A) · (Cost of misclassifying A) = (Probability of misclassifying B) · (Cost of misclassifying B)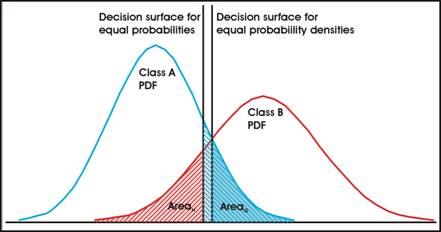
If the cost of Misclassifying A is higher than the cost of Misclassifying B, then AreaG, representing the probability of Misclassifying A, needs to be reduced, and of course this means that AreaH will increase in size.
Thus: AreaG · CostA = AreaH · CostB
We know from our discussion on probability density functions that:
so we need to adjust the decision surface by changing xd until the condition specified in the first equation above is met.
