6. Klasyfikacje
Klasyfikacja nadzorowana
Klasyfikacja nadzorowana (w przeciwieństwie do klasyfikacji nienadzorowanej) używa klas referencyjnych jako źródła dodatkowych informacji. Dzięki temu łatwiej jest zagwarantować poprawność przeprowadzonej klasyfikacji. W procesie najczęściej podejmowane są następujące kroki:
- Zdefiniowanie klas użytkowania i pokrycia terenu (takich klas spektralnych jak lasy iglaste, liściaste, woda, uprawy, itp.).
- Sklasyfikowanie pól treningowych (obszarów referencyjnych dla każdej klasy).
- Rozpoczęcie faktycznej klasyfikacji z pomocą odpowiedniego algorytmu klasyfikacyjnego.
- Weryfikacja, ocena i przejrzenie wyników.

Pola treningowe
Klasyfikacja statystyczna z wykorzystaniem tak zwanych pól treningowych musi być najpierw "nauczona". Wpierw pola treningowe wybierane są na badanym obszarze (na przykład na mapach lub zdjęciach lotniczych) i kartowane w trakcie badań terenowych. Tym samym definiowane są przykładowe obszary dla każdej klasy (na przykład klas pokrycia terenu: las iglasty, zbiorniki wodne, itp.), które będą dostępne jako punkty odniesienia dla klasyfikatora.
Metoda największego prawdopodobieństwa
Faktyczna klasyfikacja zdjęcia satelitarnego zachodzi z pomocą kompleksowych algorytmów klasyfikacyjnych, takich jak metoda największego prawdopodobieństwa, najmniejszych odległości, metody sześcienne (równoległościenne) lub też klasyfikacja hierarchiczna.
Najpopularniejszą metodą jest metoda największego prawdopodobieństwa (nawiązująca do funkcji gęstości prawdopodobieństwa). W przypadku tej metody klasyfikator próbuje odgadnąć jakie jest prawdopodobieństwo tego, iż wybrany piksel będzie przynależał do danej klasy. W sytuacji gdy piksel może przynależeć tylko do jednej grupy, algorytm dopuszcza duże odchylenia w wartości piksela od średniej wartości dla grupy (klasy). Z kolei gdy piksel może przynależeć do kilku grup, dopuszczalne odchylenia w wartościach będą zdecydowanie niższe.
Zadanie: Do której grupy powinny zostać zaklasyfikowane gwiazdki czerwona i niebieska?
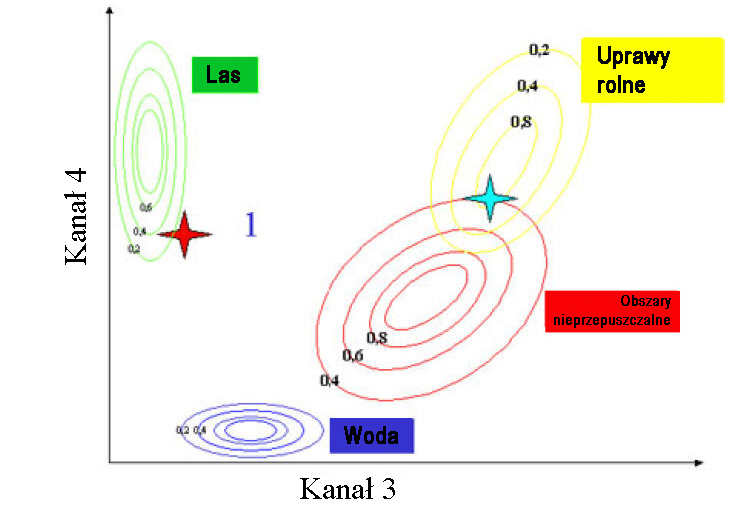
Źródło: Naumann 2008
Ocena i sprawdzanie wyników
W celu oceny/weryfikacji wyników, obliczana jest różnica prawdopodobieństwa tego, że piksel będzie przynależał do danej klasy i prawdopodobieństwa, że będzie należeć do klasy przyległej. Rezultatem jest macierz błędów, która pokazuje czy wybrany obszar testowy będzie przydatny w klasyfikacji.
